
¿Te has planteado alguna vez hacer una migración de un Datawarehouse (DWH) a un Data lake? Si es así este post, te puede dar alguna pistas de sobre como empezar a abordar el proyecto.
Para empezar antes de abordar la migración es necesario plantearse ciertas cuestiones, dado que muchas veces parece que es necesario migrar obligatoriamente debido a la presión del mercado. A largo plazo, estas soluciones presentan una serie de beneficios muy claros, como son la flexibilidad ante cambios, variedad de tipologías de datos, escalado horizontal, etc.
Sin embargo, para decantar la balanza es necesario evaluar cuestiones como si el equipo de datos es capaz de responder a las necesidades analíticas de negocio en un tiempo razonable, si se está sacando el máximo provecho a los datos o si el equipo de analítica está satisfecho con los procedimientos actuales.
Si la mayoría de las respuestas son negativas, parece clara la necesidad de llevar a cabo una migración de este tipo. Durante las siguientes líneas se expondrá una visión general con los aspectos más importantes a tener en cuenta.
Debido a la existencia de numerosos proveedores luchando por su cuota de mercado, realmente no existe una práctica recomendada establecida para realizar este tipo de migración. Además, cada organización tiene sus propias necesidades únicas y requiere un enfoque individualizado con respecto a la adaptación tecnológica.

Cuestiones básicas sobre los DataWareHouse.
El almacenamiento de datos es un método que se utiliza para almacenar datos estructurados en un esquema relacional. Las fuentes de datos son variadas y generalmente provienen de los sistemas de procesamiento de transacciones en línea (OLTP), planificación de recursos empresariales (ERP) y gestión de relaciones con el cliente (CRM), en un proceso llamado Extracción, transformación y carga (ETL). El objetivo principal del almacenamiento de datos es transformar los datos en un formato estructurado que admita la lógica empresarial y habilite las herramientas de BI para crear análisis e informes que representen «una visión de la realidad».
Dos de los tipos de esquema más comunes que se utilizan en los DWH son el esquema de copo de nieve y el esquema de estrella. Estos esquemas son cruciales para problemas específicos, como:
- Extracción de datos históricos y datos cambiantes a lo largo del tiempo
- Calidad e integridad de los datos
- Alto rendimiento de extracción y facilidad de generación de informes
Data Lake
Por su parte, el término Data Lake es relativamente nuevo, y fue haciendose más popular a medida que la realidad de los rangos de petabytes y exabytes de datos recopilados en las organizaciones, incluidos los datos de transmisión en tiempo real, los eventos en línea y los registros, necesitaban ser almacenados, manejados y analizados. Los Data Lakes pueden contener datos estructurados y no estructurados al brindar la flexibilidad para analizar datos desde diferentes ángulos y mejorar las capacidades analíticas respondiendo múltiples preguntas comerciales de una variedad de fuentes de datos almacenadas. Además, son capaces de manejar grandes volúmenes de datos almacenados.
DataWarehouse vs Data Lake
Las principales diferencias de ambos sistemas son:
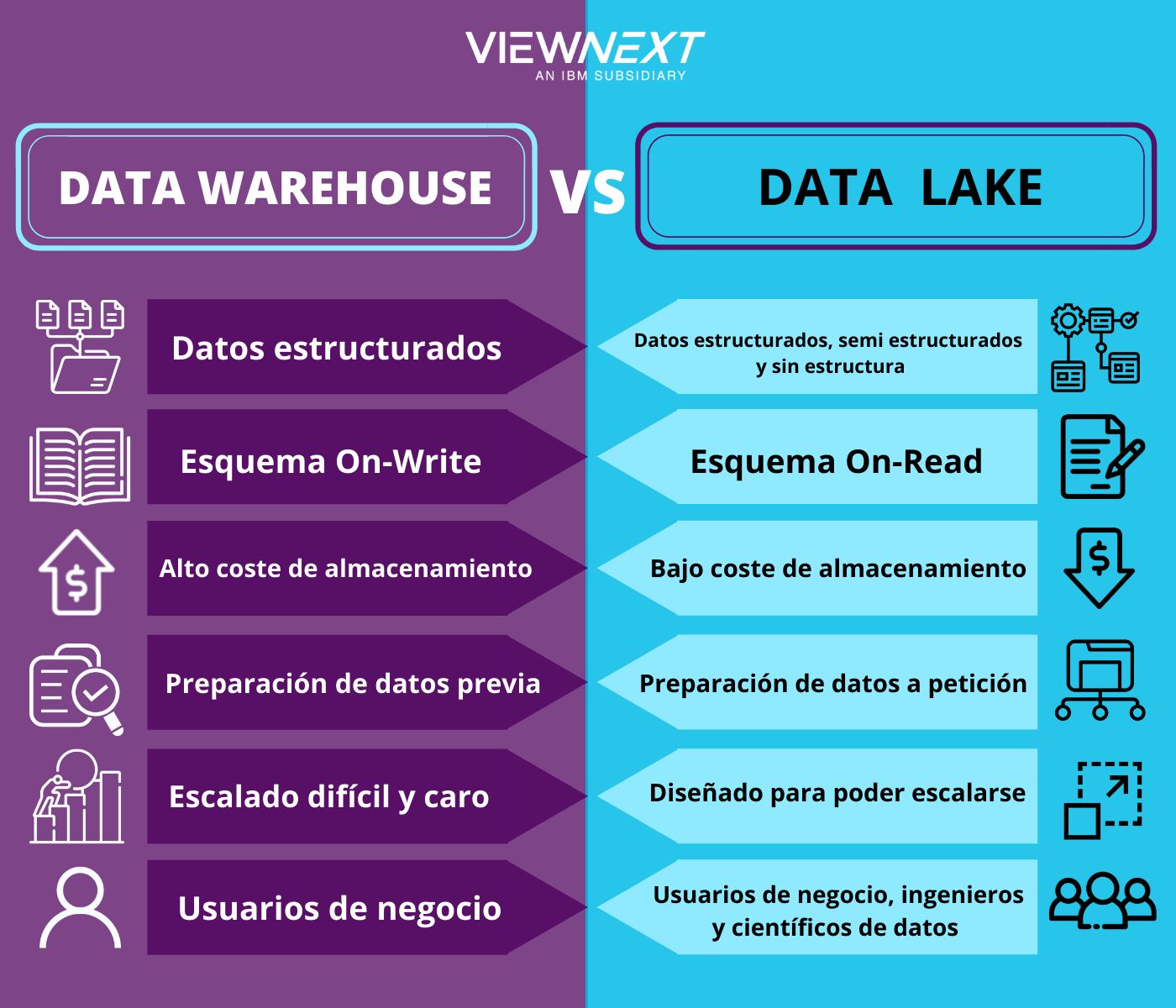
Aunque estos sistemas, como cualquier otro también presentan puntos débiles:
DataWarehouse
- Coste y tiempo de preparación y mantenimiento.
- No soporta tipos de datos no estructurados.
Data Lake
- La solución puede ser costosa desde el punto de vista informático.
- Complejidad en la creación de lectura segura de datos por usuario final.
- Gobierno del dato.
Una vez expuestas las características de ambos conceptos, puede afirmarse que no hay una respuesta única a la pregunta de qué método es preferible, ya que cada uno de ellos está diseñado para diferentes propósitos y tiene sus pros y sus contras.
¿Datawarehouse o Data Lake?
De este modo, para datos contables, ventas, inventario y clientes, resulta preferible trabajar con un DWH para lograr los números más precisos, pero, por otro lado, si se está tratando con datos provenientes de redes sociales, registros web, transmisión de datos o datos de un call-center, la opción a elegir es sin duda los Data Lakes.
En cuanto a la arquitectura a implementar se podría tomar alguna de las siguientes posibilidades:
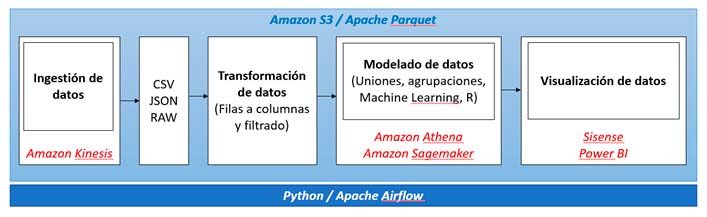
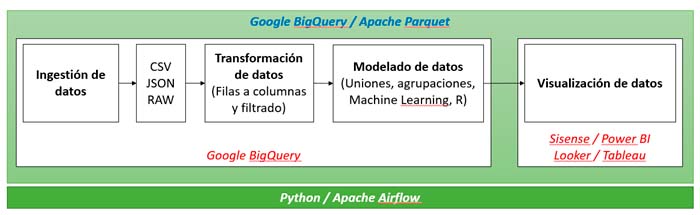
Como puede verse en los esquemas anteriores, el modelo de Data Lake de 3 etapas tiene paralelismos con la técnica de Data Warehouse, es decir, capas de duplicación (mirroring), preparación (staging) y modelado (modeling). Esta arquitectura es conveniente para mantener todo en orden. De este modo, si surge un problema de una de las capas, es más fácil comprender dónde y cómo solucionar el problema.
¿Cómo implementar esta arquitectura?
Existen diversas opciones sobre cómo implementar esta arquitectura:
Para conservar las capacidades del DWH, con un gobierno de datos completamente administrado, y aún disfrutar de los beneficios de la computación en la nube y el almacenamiento por demanda, sería posible optar por utilizar tanto Amazon Redshift como Google Big Query, aunque el principal inconveniente sería que se trata de una solución relativamente cara y que también requiere la existencia de personas en el equipo con experiencia y conocimientos específicos.
En el caso de una solución a medida, sería posible continuar usando el DWH actual y considerar la siguiente opción:
- Para equipos no familiarizados en el uso de la nube, sería buena idea comenzar agregando nuevos datos al almacenamiento, añadiéndolos a través de las capas de la arquitectura y aprendiendo cómo trabajar con una herramienta estilo Apache Airflow. Mientras tanto, se puede migrar el esquema de las tablas de Data Warehouse a la capa de modelado.
- Por su parte, para equipos familiarizados con un entorno de nube que quieren deshacerse de su proceso ETL tradicional, convendría comenzar por migrar sus consultas del proceso ETL a una arquitectura de capas, en la que la capa de Ingestión de datos se correspondería con las tablas de mirroring, la transformación de datos con las tablas de staging y el modelado de datos con las tablas de almacenamiento de datos.
Este proceso es perfecto para un DWH de «carga completa». En el caso de optar por una configuración «upsert» (UPDATEs e INSERTs), el proceso se complica y requiere algo de experiencia. También existe la técnica de dimensión lentamente cambiante, que es más difícil de administrar en Data Lakes, pero es posible.
Conclusiones
En resumen, para crear un Data Lake se debería:
- Crear la justificación empresarial adecuada y tratarla como un proyecto de negocio, no como un proyecto tecnológico.
- Construir una arquitectura que respalde los datos.
- Elegir una herramienta de gobernanza de datos.
- Establecer etapas de creación:
- Completar el Data Lake con datos sin procesar de fuentes de datos internas y externas, para soportar el uso comercial principal, al tiempo que el equipo de datos mejora sus habilidades.
- Presentar el entorno del Data Lake al equipo de científicos de datos, para que puedan probar y aprender para qué «área» de datos debe expandirse su alcance.
- Inyectar el DWH existente en el Data Lake, mientras se protegen la lógica empresarial, el esquema y los metadatos correctos. Se recomienda mantener «activo» el DWH durante un período de tiempo predeterminado, mientras se examina su rendimiento y precisión.
- Por último, acceder a todos los datos en el Data Lake, que ahora será la plataforma principal. Los datos se pueden conservar como un servicio para los usuarios y desarrolladores comerciales, siempre y cuando se aplique estrictamente la gobernanza de los datos.


