
En este artículo voy a describir la filosofía del Clean Code o Código Limpio, indicando los principios en los que se basa, y a mostrar las múltiples ventajas que tiene su uso y mostraré ejemplos de código en los que se utilizan estas técnicas.
¿Qué es?
Clean Code es una filosofía utilizada en el desarrollo de software cuyo objetivo es hacer más fácil la lectura y escritura de código. Se basa en la aplicación de técnicas sencillas con las que generamos un código claro e intuitivo que es más fácil de modificar. Es especialmente útil cuando se trabaja en grupo, ya que es posible que tu código lo tenga que modificar posteriormente otra persona.

Escribir código limpio puede implicar tanto escribir más código de lo normal como escribir menos, dependerá de las circunstancias, pero siempre dejará claro lo que quiere conseguir.
Las técnicas mencionadas anteriormente se basan en gran medida en el contenido del libro escrito en 2008 por Robert C. Martin y titulado “Clean Code: A Handbook of Agile Software Craftsmanship”. En este libro, se habla acerca de cómo generar código que al estar bien estructurado sea fácil de entender y, por tanto, sea fácil de mantener. Es un libro útil para cualquier desarrollador, independientemente de la experiencia que tenga. Si eres un desarrollador con experiencia seguro que hay detalles que no tenías en cuenta y que puedes poner en práctica para mejorar. Sin duda resultará mucho más útil para desarrolladores de software principiantes porque les proporcionará una buena base para generar un código de calidad.
Principios generales
A continuación, voy a describir las principales reglas en las que se basa el Clean Code:
Nombres descriptivos
La idea de este principio es que las variables, funciones, clases, métodos, etc… tienen que tener un nombre que exprese su intención. Es decir, solo con leer el nombre de un objeto deberíamos saber cuál es su propósito. Puede parecer algo insignificante, pero es muy importante para entender el código. Un ejemplo muy sencillo, pero con el que se entiende bien el concepto es el siguiente: si vamos a declarar una variable para almacenar el campo ZLSCH (vía de pago) de la tabla BSID, no lo llamemos lv_zlsch sino lv_viaPago.
Si, por ejemplo, una función necesita tener un nombre largo para que se entienda su función, adelante con ese nombre. No hay problema porque un objeto tenga un nombre largo, porque así evitaremos tener que adentrarnos en la función para saber qué es lo que hace.
Para la nomenclatura de los objetos, podemos usar la práctica de escritura CamelCase. Consiste en unir dos o más palabras sin dejar espacios entre ellas y diferenciándolas en que la primera letra de cada palabra la ponemos en mayúscula (excepto la primera).
Regla del boy scout
Este principio es muy simple y consiste, aplicándolo a la codificación, en dejar el código que modifiques más limpio que como lo encontraste. Es decir, si modificas un código y ves cosas que no cumplen con el Clean Code, cámbialas para mejorar la calidad del código (aunque no formen parte de tu modificación).
Principio Don’t Repeat Yourself (DRY)
La traducción exacta de este principio sería “No te repitas a ti mismo”. Aplicado al área de la programación, consistiría en un mismo código que se repite en más de un sitio. Es habitual, pero es muy desaconsejable porque empeora la mantenibilidad del código. Además, es más probable que a causa de lo anterior, se produzcan errores, ya que se nos puede olvidar realizar un cambio en todos los sitios en donde esta ese código.
Solución para ello: crear una función que realice ese código y llamarla en todos los puntos donde sea necesario. De esta manera, si posteriormente hay que realizar un cambio solo habrá que hacerlo en un sitio, en la función.
Funciones
Una regla fundamental es que una función realice una sola cosa, y como hemos dicho anteriormente, el nombre de dicha función tiene que indicar cuál es esa cosa. Con ello generamos que cualquier programador pueda saber lo que realiza la función sin tener que mirar su código.
Tiene que ser lo más pequeña posible. Si una función es más grande de lo que debería, lo ideal es generar funciones que hagan distintas partes de ese código. Gracias a ello conseguimos que el código sea más reutilizable.
También es aconsejable usar el menor número posible de argumentos de entrada/salida, facilitando así entender lo que hace una función y también provocará que el tiempo usado para probarla sea menor porque las combinaciones posibles también son menores.
Otro consejo es utilizar siempre excepciones en vez de devolver códigos de error, porque con ellas queda más claro la causa del error sin tener que añadir más código o comentarios.
Estructura del código
Estructurar de manera clara el código provoca que sea más fácil de leer y por tanto de mantener. A continuación, expongo ideas de como estructurar el código:
- Nuestras diferentes variables deben declararse todas juntas al principio de la función, método, etc…
- Cada sentencia del código debe ir en una línea.
- Por lo tanto, las sentencias relacionadas deben estar en líneas consecutivas para separarlas del resto de código.
- Cada grupo de sentencias relacionadas deben separarse por líneas en blanco.
- Aunque no haya establecido un límite máximo de caracteres por línea, no es aconsejable escribir líneas de código muy largas porque dificulta la lectura rápida del código.
- Es importante tabular el código correctamente.
Todas estas ideas tan simples pueden mejorar mucho la lectura del código porque ahorramos tiempo a la hora de modificarlo. A la hora de trabajar en un equipo es muy aconsejable que todos sus miembros sigan estas directrices para no perder tiempo a la hora de extender el código.
No penalizar el rendimiento
Cuando se modifica un objeto existente, es importante no hacerlo de manera incorrecta y por tanto penalizando el rendimiento de ese programa, función, método, etc… Para ello, hay que revisar el objeto para ver el mejor sitio posible donde hacer la modificación. A pesar de que eso conlleve algo más de tiempo, es beneficioso a la larga porque nos ahorramos posteriormente tener que revisar el rendimiento de dicho objeto. Después de haber seguido todos los principios del código limpio, revisar ese objeto no nos llevará tanto tiempo como podríamos pensar.
Ventajas de usar Clean Code
Son múltiples las ventajas de usar estas técnicas. A continuación, comento algunas de ellas:
- El código es más fácil de leer para cualquier persona, sobre todo para aquella que no es quien lo ha desarrollo, es muy útil cuando se trabaja en equipo.
- El código es más fácil de mejorar y por tanto de mantener.
- Una situación bastante común es, debido a no entender bien el código ya desarrollado, implementar un nuevo cambio añadiendo código al final del objeto. Esto se evita utilizando estas técnicas, ya que el tiempo empleado en ver el punto a tocar es menor si se usan estas técnicas. De esta manera, añadimos el nuevo código en el punto correcto y en poco tiempo.
- La calidad del código aumenta considerablemente y, por tanto, la calidad de nuestro trabajo.
- Usando estas técnicas, se benefician no solo los demás, sino también nosotros mismos. Piensa que puedes ser tú mismo quien tenga que modificar un objeto (por ejemplo) un año después de la última modificación. ¿Crees que te acordaras de porque escribiste esas líneas de código? De esta manera, solo tendrás que leer el código para entenderlo y podrás realizar las modificaciones sin ningún problema.
- En definitiva, una ventaja esencial es que con estas prácticas generamos código limpio para todo el mundo.
Ejemplos prácticos de Clean Code
Ahora voy a exponer ejemplos de cada una de las principales reglas del Clean Code:
Nombres descriptivos
En caso de tener que recuperar el campo BUKRS de la tabla de base de datos EVER para posteriormente mostrarlo en un ALV. Nombraremos esa variable con un nombre que nos permita saber que almacena sin tener que ir a ver la descripción de ese campo en la tabla de BBDD. Por tanto, en vez de generar un código como este:
DATA: lv_bukrs TYPE ever-bukrs.
SELECT SINGLE bukrs INTO lv_bukrs FROM bukrs WHERE vertrag EQ pi_contrato.
Debemos generar el siguiente:
DATA: lv_sociedad TYPE ever-bukrs.
SELECT SINGLE bukrs INTO lv_sociedad FROM bukrs WHERE vertrag EQ pi_contrato.
Otro ejemplo lo podríamos poner para los nombres de las funciones. Al generar una función para obtener el número de orden a partir del número de objeto, tenemos que ponerle un nombre que nos permita saberlo sin tener que entrar a mirar su código. Por tanto, en vez de ponerle el nombre (por ejemplo) “ZGet_aufnr”, deberíamos nombrarla “ZGet_Aufnr_From_Objnr”.
Regla del boy scout
Como ejemplo podría poner el siguiente: tenemos que añadir en un form de un programa una lógica para separar en 2 campos el valor de un campo y su descripción (actualmente se están mostrando concatenados en un solo campo). Y resulta que está obteniendo las descripciones del campo en una tabla interna normal.
¿Te limitarías a realizar tu cambio o mirarías si esta tabla se podría hacer por ejemplo hashed (tabla que es más rápida y por tanto mejora el rendimiento)? En eso consiste esta práctica. Tardarías algo más en hacer el cambio, ¡pero generaras un código de más calidad y más óptimo!
Principio Don’t Repeat Yourself
Hace muy poco tiempo en el trabajo usé este principio. Me pidieron modificar dos funciones para añadir en ambas un cambio consistente en cambiar la unidad de servicio en la operación de Servicios a certificar. La opción más rápida sería haber cambiado ambas funciones añadiendo las llamadas a las BAPI correspondientes. Sin embargo, de esa manera no hubiera cumplido este principio. Lo que hice fue generar una función Z en donde añadí las llamadas a las BAPI y, posteriormente, en ambas funciones llamé a la nueva función creada.
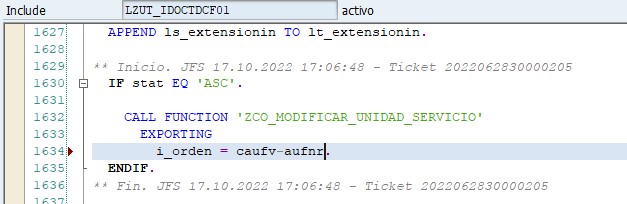
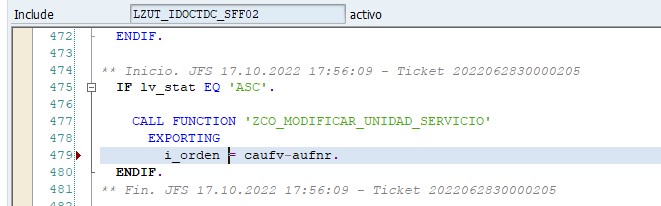
Me llevó algo más de tiempo codificarlo, pero posteriormente gané tiempo porque en las pruebas al tener que realizar cambios, solo tuve que realizarlos en un sitio. Además, de esta manera evité el problema de olvidarme de realizar los cambios en alguna de las dos funciones.
Funciones
Un ejemplo podría ser una función que realice ciertos cálculos aritméticos a partir de campos de una tabla de BBDD y que posteriormente actualice un registro de esa tabla. En vez de generar una sola función que haga ambas tareas, lo ideal en este caso, es generar una función para la actualización del registro y otra función que realice los cálculos aritméticos. Vamos a verlo en código.
FUNCTION ZGET_MODIFY_DUE_DATE.
CLEAR: lv_fecha_base_vencimiento, lv_dias_descuento. SELECT zfbdt zbd1t INTO (lv_fecha_base_vencimiento, lv_dias_descuento) FROM bsik UP TO 1 ROWS WHERE lifnr EQ i_proveedor. ENDSELECT.
CLEAR lv_fecha_vencimiento. lv_fecha_vencimiento = lv_fecha_base_vencimiento + lv_dias_descuento.
CLEAR ls_info_proveedor. SELECT SINGLE * INTO ls_info_proveedor FROM zinfo_proveedor WHERE lifnr EQ i_proveedor. IF sy-subrc EQ 0.
ls_info_proveedor-zfecha_vencimiento = lv_fecha_vencimiento. UPDATE zinfo_proveedor FROM ls_info_proveedor. IF sy-subrc EQ 0.
CALL FUNCTION 'BAPI_TRANSACTION_COMMIT' EXPORTING wait = 'X'. ENDIF. ENDIF.
ENDFUNCTION.
En vez de crear una sola función con todo ese código, lo ideal es crear dos funciones que hagan cada una de las partes.
FUNCTION ZGET_DUE_DATE.
CLEAR: lv_fecha_base_vencimiento, lv_dias_descuento. SELECT zfbdt zbd1t INTO (lv_fecha_base_vencimiento, lv_dias_descuento) FROM bsik UP TO 1 ROWS WHERE lifnr EQ i_proveedor. ENDSELECT.
CLEAR e_fecha_vencimiento. e_fecha_vencimiento = lv_fecha_base_vencimiento + lv_dias_descuento.
ENDFUNCTION.
FUNCTION ZMODIFY_DUE_DATE.
CLEAR ls_info_proveedor. SELECT SINGLE * INTO ls_info_proveedor FROM zinfo_proveedor WHERE lifnr EQ i_proveedor. IF sy-subrc EQ 0.
ls_info_proveedor-zfecha_vencimiento = i_fecha_vencimiento. UPDATE zinfo_proveedor FROM ls_info_proveedor. IF sy-subrc EQ 0.
CALL FUNCTION 'BAPI_TRANSACTION_COMMIT' EXPORTING wait = 'X'. ENDIF. ENDIF.
ENDFUNCTION.
Estructura del código
¿Entiendes mejor este código?
IF x_obj-trig-etrg-abrvorg2 EQ '03'. DATA: lv_status_contrato TYPE ever-bstatus. CLEAR lv_status_contrato. SELECT bstatus INTO lv_status_contrato FROM ever UP TO 1 ROWS WHERE vertrag EQ i_vertrag.ENDSELECT. IF ( lv_status_contrato EQ '08' OR lv_status_contrato EQ '09' ). DATA: lv_status_orden_calculo TYPE etrg-trigstat. CLEAR lv_status_orden_calculo. SELECT trigstat INTO lv_status_orden_calculo FROM etrg UP TO 1 ROWS WHERE anlage EQ i_anlage AND abrdats EQ i_abrdats.ENDSELECT. IF lv_status_orden_calculo EQ '01'. DATA: lv_mensaje TYPE string. * No permito la generación del cálculo CLEAR lv_mensaje_error. lv_mensaje_error = 'Cálculo de baja a la espera por lectura de ciclo anterior.'. MESSAGE lv_mensaje_error TYPE 'I'. RAISE general_fault. ENDIF. ENDIF. ENDIF.
¿O este otro?
DATA: lv_status_contrato TYPE ever-bstatus, lv_status_orden_calculo TYPE etrg-trigstat, lv_mensaje TYPE string.
IF x_obj-trig-etrg-abrvorg2 EQ '03'.
CLEAR lv_status_contrato. SELECT bstatus INTO lv_status_contrato FROM ever UP TO 1 ROWS WHERE vertrag EQ x_obj-bill-erch-vertrag. ENDSELECT.
IF ( lv_status_contrato EQ '08' OR lv_status_contrato EQ '09' ).
CLEAR lv_status_orden_calculo. SELECT trigstat INTO lv_status_orden_calculo FROM etrg UP TO 1 ROWS WHERE anlage EQ x_obj-trig-etrg-anlage AND abrdats EQ x_obj-pbill-erch-abrdats. ENDSELECT.
IF lv_status_orden_calculo EQ ’01’.
* No permito la generación del cálculo CLEAR lv_mensaje_error. lv_mensaje_error = 'Cálculo de baja a la espera por lectura de ciclo anterior.'. MESSAGE lv_mensaje_error TYPE 'I'. RAISE general_fault.
ENDIF. ENDIF. ENDIF.
Pues creo que aquí no hay mucho que decir. El segundo código se lee y se entiende mucho más rápido que el primero.
No penalizar el rendimiento
Para mostrar esta práctica se podría poner como ejemplo un cambio a realizar en un programa para mostrar el campo nuevo INVOICING_PARTY de la tabla de BBDD EVER en el ALV de salida que ya genera dicho programa.
Puede que ese programa sea muy extenso y que realice muchos select para la obtención de datos. Y puede que, para no perder tanto tiempo, no revisemos todos esos select y se nos escape que el programa ya busca en esa tabla de BBDD. Añadiríamos otro select a la misma tabla para obtener el nuevo campo. El cambio correcto sería modificar la consulta actual para recuperar también el campo nuevo.
En caso de elegir la opción incorrecta, podemos penalizar mucho el rendimiento. Debido a que no sería solo la nueva consulta a base de datos, sino también una nueva tabla interna para guardar los datos con su consecuente READ TABLE nuevo… Es decir, duplicaríamos muchas sentencias innecesarias. Contamos con una tabla grande puede que aumente considerablemente el tiempo de ejecución y por tanto las quejas de los usuarios. Usando las normas del Clean Code en este programa no se tardaría tanto en entender…
Con todo lo expuesto, podemos concluir que seguir estas prácticas de fácil aplicación mejoran la calidad del código, además de ahorrarnos tiempo al facilitarnos la lectura y por tanto el mantenimiento del código. Estas prácticas son útiles independientemente de la experiencia del programador y permiten que pueda extender el código cualquier persona, aunque no sea el autor.


