
Los datos se han convertido en la influencia más dominante en las operaciones, las interacciones y los procesos en las industrias de todo el mundo. Esto afecta a todos los departamentos existentes en una organización y abre las puertas a que nuestros clientes exijan una conectividad personalizada. Estos datos contribuyen a generar una gran cantidad de información, por ejemplo con cada clic en sus dispositivos personales o usando sus tarjetas de crédito, transformando esa información en conocimiento que permita un mejor posicionamiento en el negocio de las empresas.
Cuando los sistemas de aprovisionamiento empezaron a presentar problemas de procesamiento con volúmenes masivos de datos, empezó a introducirse un término ahora conocido por todos: Big Data. En esencia consistía en la creación de nuevas herramientas que abordaban esta situación, teniendo capacidad para procesar TB de datos de forma paralela y con servidores no muy potentes. Pero ¿era suficiente?

En un primer lugar Big Data, mediante el uso de procesos batch, fue capaz de solventarlo y generar conocimiento con un gran volumen de datos heterogéneos. Con el paso del tiempo y la revolución digital se generó la necesidad de tener los datos real-time debido a que las decisiones con datos con un decalaje de 24 horas ya no eran suficientemente consistentes para esta toma. Por ello el ecosistema Big Data viró a un sistema de tratamientos de datos en real-time y nació una de las herramientas estrella más populares presente en todas las arquitecturas actuales de streams de datos: Apache Kafka.
¿Qué es Apache Kafka?
Apache Kafka nació como alternativa a las colas de mensajería tradicionales que actualmente existen, como Artemis o RabbitMQ. Ésta última fue desarrollada internamente por la compañía más importante de redes sociales profesionales, LinkedIn, inicialmente creada para dar solución al principal problema que tenía la compañía: procesar 1.4 billones de mensajes al día. Un tiempo después de finalizar su desarrollo, LinkedIn liberó y donó esta herramienta a Apache Foundation convirtiéndose en un proyecto Open Source.
La razón por la que Apache Kafka puede manejar billones de mensajes al día de forma extremadamente eficiente, al contrario que las colas tradicionales, es debido principalmente a su arquitectura. Dicha arquitectura está basada en una plataforma de transmisión de datos de tipo publicador/consumidor compuesto por 3 elementos fundamentales:
- Productor: es quien produce el dato o fuente de datos. Por ejemplo, Twitter.
- Consumidor: es quien lee ese dato (aplicación), puede ser uno o varios subscritores.
- Topic: elemento que guarda el dato producido por el productor para que el consumidor lo lea.
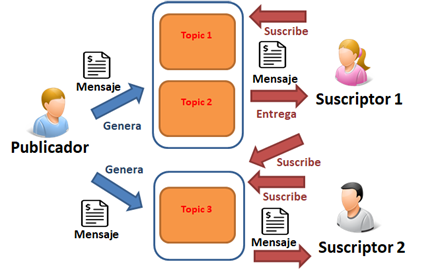
Fuente de la imagen: BIGDATALAM
Como nos muestra la imagen anterior, tenemos un Publicador que es el generador de información, como por ejemplo podrían ser los clics de un cliente en una página web, que se encarga de escribir en el Topic, de manera que el consumidor pueda acceder a demanda a los datos ahí almacenados.
En Kafka podemos tener millones de topics que se almacenan de manera particionada para aumentar el rendimiento de procesamiento en su lectura y escritura. Desde Viewnext trabajamos con nuestros clientes para hacer más eficientes sus arquitecturas, para ello la elección de un número adecuado de particiones es fundamental, por lo que tenemos que cuantificar el volumen de datos por segundo que se desea procesar para poder calcular la proporción más eficiente de estas particiones.
Una vez almacenada la información en el topic, tendríamos disponible toda la información para poder realizar el consumo de ella. Una de las ventajas que tiene Kafka sobre las colas de mensajería tradicionales, es que la misma información puede ser consumida por diferentes subscritores o consumidores. Esta característica es muy importante, ya que cada consumidor que necesite esa información no interfiere en los demás, debido a que Kafka hace una ingesta de información, pero ésta es consumida tantas veces como se necesite por las diferentes aplicaciones.
¿Streaming de datos?
La mayoría de nuestros clientes trabaja con cuadros de mando con un desfase de 24 horas, el cual muestra en la mayoría de los casos información no actualizada y obtenida con procesamientos pesados, incluso con agregaciones de datos que hacen que se diluya el detalle de la información. Con la llegada del streaming empieza la revolución de las visualizaciones, haciendo posible consumir la información desde que ésta se produce en menos de 10 segundos. Gracias a esta capacidad de respuesta de la información, algunos de nuestros clientes ya están migrando parte de sus sistemas tradicionales a estas nuevas arquitecturas. Y es que esta migración es un cambio de arquitectura total, ya que utilizando las actuales herramientas de colas de mensajería tradicionales nos causaría muchísimos problemas poder realizar grandes ingestas de datos sin tener encolamientos.
En una arquitectura tradicional, una de las partes más críticas es la ingesta de información, debido al gran volumen de datos y a la criticidad de ella, sin datos no hay procesamiento ni visualizaciones. Es por ello que una de las características a tener en cuenta en una implantación de arquitectura de Streaming de datos, es la utilización de herramientas que sean resistentes al fail/over sin pérdida de datos.
Dentro de esta nueva arquitectura basada en tecnologías Big Data, la utilización de Kafka es clave, ya que está preparado no solo para realizar una gran ingesta de datos, sino que además aporta una gran robustez al procesamiento. Actualmente Kafka está evolucionando para convertirse, no solo un gran ingestador de datos, sino en una solución robusta para realizar procesamiento en tiempo real haciéndose más completa simplificando las arquitecturas nuevas. Este nuevo procesamiento se puede realizar gracias al reciente lanzamiento, por parte de Confluent, de la herramienta llamada KSQL.
¿Cómo funciona KSQL?
KSQL está integrado en el ecosistema Kafka, siendo éste un suscriptor más de la información que se ingesta en tiempo real. Como cualquier subscritor, lee el topic pero tiene la capacidad de realizar muchas transformaciones en línea. Esta funcionalidad hace que el dato, cuando sale del ecosistema Kafka, no necesite ningún procesamiento y esté listo para ser mostrado o consultado por herramientas front-end.
En la imagen de abajo se describe la arquitectura que tiene KSQL donde su única fuente de lectura y escritura es Kafka.
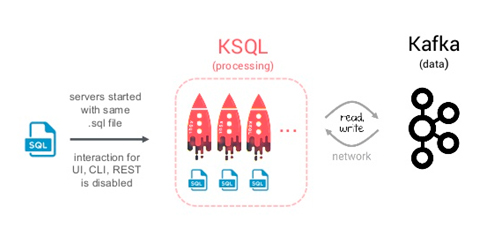
Fuente de la imagen: Kai Wähner (Confluent) – Slideshare
Como hemos comentado anteriormente, KSQL nos da la opción de realizar transformaciones de datos, pero no solo esto, sino que además dispone de la posibilidad de realizar agregaciones, joins y filtrados en tiempo real. Un caso de uso claro de esta potencia de realizar procesamientos es la posibilidad de, a la vez que estamos ingestando información, mostrar como resultado un conteo constante de cuantos pedidos, interacciones de cada cliente o facturación está produciéndose prácticamente en tiempo real.
Otro caso de uso desplegado para utilizar KSQL en uno de nuestros clientes del sector bancario, fue aprovechar las bondades de este sistema siendo capaces de poder detectar fraudes de pagos y alarmar en tiempo real de esta actividad fraudulenta. Esto se consiguió solo con sentencias SQL y una de las funcionalidades que tiene KSQL, Windowing, que consiste en que durante una fracción de tiempo se pueden analizar todos los pagos que se están realizando y ver simultaneidad de pagos en diferentes ubicaciones en tiempo real.
Beneficios
El principal beneficio, con la reciente liberación del proyecto KSQL, es su capacidad de procesar sin necesidad de utilizar herramientas como Spark Streaming o Flink para realizar transformaciones sencillas. Un ejemplo de transformaciones es la realización de Joins, este simple hecho de realizar una unión de topics en tiempo real, hace que podamos disponer de la información final sin salir de Kafka, ahorrando tiempos de red y procesamiento. Con esta mejora los proyectos real-time son mucho más rápidos de implementar, ya que no es necesario realizar desarrollos a medida ni tener un gran conocimiento de lenguajes de programación funcional como es Scala. Solamente con conocimientos de SQL se pueden realizar muchas operaciones que anteriormente eran imposibles sin una codificación adicional en otros lenguajes.
Otro de los grandes beneficios de KSQL es su robustez: tener una arquitectura pensada en fail/over hace que KSQL garantice que el dato se lee una vez y que no haya perdidas. En muchas de las aplicaciones que se desarrollan, la gestión del dato se hace compleja realizando continuos contrastes de información para garantizar que la información es válida.
KSQL es un proyecto que está más vivo que nunca, lo que hace que reciba constantes actualizaciones y esté en pleno crecimiento, por lo que cada nueva versión aumenta sus capacidades con el fin de sustituir a los complejos procesos de Spark. Nuestro conocimiento sobre esta tecnología y su versatilidad, nos permite posicionarnos en la vanguardia del Data Streaming al lado de nuestros clientes.


