
Si alguna vez has desarrollado microservicios, o cualquier otra arquitectura distribuida, o experimentado con algunos tipos de base de datos NoSQL, es probable que hayas oído hablar de cosas como «consistencia eventual”, transacciones tipo BASE y de SAGAs. Estos términos se refieren a un modelo transaccional donde prima la escalabilidad y la disponibilidad por encima de la consistencia.
En este artículo, vamos a profundizar en qué consiste la consistencia eventual, cómo funciona, y cuáles son las ventajas y desventajas de utilizar este modelo de consistencia comparado con el modelo de consistencia estricta y por qué es preferible su uso en transacciones distribuidas como las que pueden darse en una aplicación basada en microservicios.

¿Qué es la consistencia transaccional?
La consistencia transaccional es un modelo de consistencia de datos que se basa en el uso de transacciones ACID. Una transacción es una serie de operaciones que se ejecutan como una unidad indivisible de trabajo (unit of work). Este tipo de transacción debe cumplir con las propiedades ACID:
- Atomicidad: una transacción se realiza en su totalidad, no se aceptan cambios parciales. Si una operación dentro de la transacción falla, todas las operaciones realizadas dentro de la transacción se deshacen.
- Consistencia: una transacción mantiene la integridad de los datos. Si una transacción se completa correctamente, el estado del sistema se mantiene consistente.
- Aislamiento (Isolation): una transacción se ejecuta de forma aislada, lo que significa que los cambios realizados en una transacción no son visibles para otras transacciones hasta que se completen.
- Durabilidad: los cambios realizados en el contexto de una transacción persisten si ésta ha terminado correctamente.
Estas propiedades las tenemos de “gratis” cuando desde nuestras aplicaciones utilizamos cualquier API de acceso a una base de datos relacional. Por ejemplo, en Java tenemos la api JDBC que establece la demarcación de una transacción tipo ACID a través de la interfaz java.sql.Connection:
- Marcamos la conexión con la que ejecutaremos la lista de sentencias con la propiedad auto-commit a false.
- Ejecutamos la lista de sentencias.
- Invocamos el método commit (o rollback en caso de producirse un error en el paso 2) de la conexión.
Las complicaciones aparecen cuando este conjunto de operaciones a sincronizar dentro de una transacción se ejecuta en diferentes nodos.
¿Cuáles son las propiedades de un sistema distribuido?
Los sistemas distribuidos pueden categorizarse en función de los siguientes atributos:
- Consistencia
La consistencia en este contexto se refiere a la capacidad de un sistema distribuido para garantizar que todas las lecturas recibirán la última escritura o un error, independientemente del nodo que responda. Sin embargo, es importante tener en cuenta que esta propiedad no es lo mismo que la Consistencia en el contexto de transacciones ACID, la cual se refiere solo a la integridad de los datos (algo que ya asumimos que de una manera u otra cualquier modelo lo va a asegurar).
- Disponibilidad (Availability)
Hace referencia a si un sistema distribuido garantiza que cada solicitud recibirá una respuesta, aunque ésta no devuelva la última versión de los datos.
- Tolerante a Particiones (resiliencia)
Esta es la capacidad de un sistema para funcionar incluso si hay algún nodo fuera de servicio. Los datos se encuentran segmentados y repartidos entre los distintos nodos del sistema.
No obstante, existe una limitación estudiada y recogida en el Teorema CAP, que dice que un sistema distribuido solo podrá optar a combinar como máximo dos de las tres propiedades descritas:

En general, en arquitecturas como la de microservicios, optaremos por una combinación de propiedades que facilite la escalabilidad y resiliencia del sistema: escogeríamos la combinación Disponibilidad y Tolerancia a Particiones por encima de la Consistencia estricta.
¿Qué es un tipo de transacción BASE?
En una arquitectura de microservicios, cada microservicio dispone de su propia base de datos. No obstante, lo normal es que existan flujos de negocio complejos que requieran de la ejecución coordinada de varias operaciones repartidas en distintos microservicios.
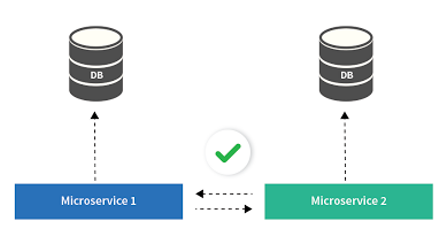
Una posible solución sería utilizar una transacción distribuida tipo ACID utilizando algún tipo de protocolo como el two-phase-and-commit (https://en.wikipedia.org/wiki/Two-phase_commit_protocol). El problema de este enfoque es que este tipo de protocolos mantiene bloqueados recursos hasta completarse la transacción, por lo que la tendencia seria a que la aplicación se ralentizase conforme aumentase el número de transacciones ejecutadas de manera concurrente. Esto sería el precio a pagar por disponer de una consistencia de datos estricta.
Para evitar esto, y que nuestra solución sea mucho más escalable, lo recomendable sería adoptar un tipo de transaccionalidad con unas características de consistencia más relajadas. Deberíamos emplear así un tipo de transacciones con las siguientes características:
- Básicamente disponible
“El sistema va a responder siempre (aunque devuelva un error).”
- Estado Soft
“El sistema aún en reposo, puede estar ejecutando cambios en su estado. Las réplicas pueden no estar sincronizadas en un momento dado.”
- Consistencia eventual
“Se asegura la consistencia de datos al cabo de un tiempo.”
Son las conocidas como transacciones de tipo BASE.
¿Qué es la consistencia eventual?
En los sistemas distribuidos, los datos se almacenan y procesan en varios nodos diferentes, lo que significa que pueden ocurrir varias cosas al mismo tiempo. En algunos casos, estos nodos pueden no tener la misma información en todo momento, lo que puede llevar a problemas de consistencia.
La consistencia eventual es un modelo de consistencia de datos que permite a los sistemas distribuidos funcionar de manera consistente, aunque los nodos no tengan la misma información en todo momento.
En lugar de garantizar que todos los nodos tengan la misma información en todo momento, este modelo permite que los nodos tengan información ligeramente desactualizada temporalmente y se asegura de que los cambios se propaguen a todos los nodos con el tiempo. Esto quiere decir que si el sistema deja de recibir peticiones de escritura se asegura que, transcurrido un tiempo, segundos digamos, todos los nodos habrán sincronizado el estado y tendrán la misma vista del estado.
¿Cómo funciona la consistencia eventual?
La consistencia eventual funciona utilizando la propagación de actualizaciones de datos a través de todos los nodos en el sistema. Cuando un nodo actualiza un dato, se asegura de que la actualización se propague a través de todos los nodos lo antes posible.
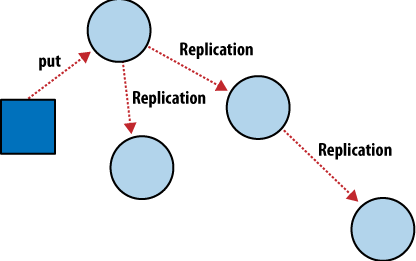
Fuente: https://www.learncsdesign.com/an-overview-of-eventual-consistency/
Sin embargo, esta propagación de actualizaciones no es inmediata y lo normal es que exista un retraso en la propagación, lo que significa que los nodos pueden tener información ligeramente desactualizada durante un periodo de tiempo (habitualmente muy corto). Este retraso en la propagación de actualizaciones es una de las razones por las que se llama «consistencia eventual».
A medida que se propagan las actualizaciones, los nodos se actualizan y la consistencia se va logrando con el tiempo. Sin embargo, debido a que el sistema no garantiza que todos los nodos tengan la misma información en todo momento, pueden ocurrir conflictos de datos. Por lo tanto, los desarrolladores deben asegurarse de que su aplicación sea capaz de manejar estos conflictos de manera adecuada.
Ventajas y beneficios de la consistencia eventual
La consistencia eventual tiene varias ventajas y beneficios en comparación con otros modelos de consistencia, como la consistencia fuerte. A continuación, se presentan algunas de las principales ventajas:
- Escalabilidad: La consistencia eventual permite que los sistemas distribuidos sean altamente escalables, lo que significa que pueden manejar grandes volúmenes de datos y usuarios sin degradar su rendimiento.
- Disponibilidad: Debido a que la consistencia eventual no requiere que todos los nodos tengan la misma información en todo momento, los sistemas pueden ser más tolerantes a fallos y más disponibles en general.
- Reducción de la latencia: La consistencia eventual puede reducir la latencia de los sistemas distribuidos, ya que los nodos no necesitan esperar a que se actualicen todos los demás nodos antes de responder a una solicitud.
Estas ventajas están alineadas con los objetivos que nos marcamos cuando optamos por utilizar microservicios en el diseño de nuestras aplicaciones.
Desventajas de la consistencia eventual
Aunque la consistencia eventual puede ser una solución útil para algunos sistemas distribuidos, también tiene varias desventajas que pueden limitar su uso en ciertos casos. Algunas de las desventajas más comunes de la consistencia eventual son las siguientes:
- No garantiza la consistencia en tiempo real: La consistencia eventual se basa en la idea de que los sistemas eventualmente se pondrán al día y tendrán una versión coherente de los datos, pero esto no se produce en tiempo real. Esto significa que, en algunos casos, los usuarios pueden ver versiones desactualizadas de los datos, lo que puede ser un problema para aplicaciones que requieren una precisión y actualización en tiempo real.
- Puede ser difícil de programar: La consistencia eventual puede ser difícil de programar porque los programadores deben considerar la posibilidad de que los datos estén desactualizados en cualquier momento y tener en cuenta este hecho en su código (acciones compensatorias, bloqueos lógicos de registros, etc). Esto puede complicar el diseño de aplicaciones y aumentar la complejidad del código.
- Requiere resolución de conflictos (contramedidas): Cuando se utiliza la consistencia eventual, es posible que se produzcan conflictos cuando varios nodos actualizan la misma información de forma simultánea. Resolver estos conflictos puede ser complicado y requerir un alto nivel de sofisticación en el software, lo que aumenta la complejidad del sistema.
- Puede ser difícil de depurar: Debido a la naturaleza de la consistencia eventual, puede ser difícil determinar la causa de los problemas de los datos y depurar la aplicación. Esto se debe a que los datos pueden cambiar en cualquier momento y pueden tardar algún tiempo en converger a una versión coherente.
¿Qué es una SAGA?
Una SAGA es un patrón de diseño de software utilizado para coordinar transacciones que involucran varios microservicios. SAGA significa «Arquitectura de transacciones por pasos compensatorios», y es una forma de garantizar la consistencia transaccional en sistemas distribuidos que utilizan el modelo BASE en lugar del modelo ACID.
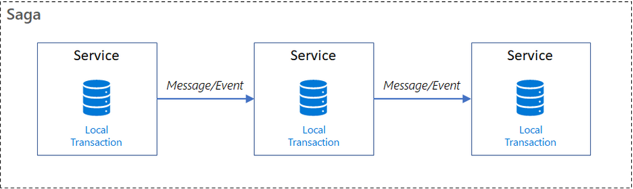
El diagrama anterior representa una SAGA como una secuencia de transacciones locales, cada una de ellas ejecutadas en el contexto de un microservicio. Cada transacción local actualiza la base de datos y publica un mensaje o evento para activar la siguiente transacción local de la saga. Si una transacción local falla porque viola una regla de negocio, la SAGA ejecuta una serie de transacciones compensatorias que deshacen los cambios realizados por las transacciones locales anteriores. Las transacciones compensatorias deben diseñarse para permitir su re ejecución de forma segura, esto es, que tenga la propiedad idempotente.
Características de una SAGA
Las SAGAs presentan unas características AC(I)D.
- Atómica: en el sentido de que al final de la SAGA todos los cambios en los diferentes contextos se habrán consolidado o se habrán retrocedido (compensado)
- Consistencia: en este caso hablamos de “consistencia eventual” descritas en las transacciones de tipo BASE
- Durables: Las transacciones locales ejecutadas en cada contexto aseguran la perdurabilidad de los cambios.
La falta de Aislamiento como propiedad intrínseca de una SAGA nos obliga a tomar medidas contra los siguientes fenómenos:
- Dirty Reads: Una transacción hace la lectura de una fila de un registro que ha sido modificada por otra SAGA pendiente también de finalizar.
- Lost Updates: dos transacciones locales pertenecientes a dos SAGAS distintas sobrescriben el mismo registro.
- Non-repeatable reads: dos lecturas del mismo registro durante la ejecución de una misma SAGA no obtienen el mismo valor.
Una medida habitual para minimizar estos efectos es la de emplear el bloqueo semántico (semantic lock). Se basa en la utilización de estados tipo *-PENDING en los registros hasta que se complete la SAGA y comprobar en nuestras transacciones este estado antes de continuar.
Tipos de SAGA
Existen varios tipos de implementaciones de SAGA, cada uno con sus propias ventajas y desventajas. Algunos de los tipos más comunes incluyen:
- SAGA coreografiada: En una SAGA coreografiada, cada microservicio es responsable de coordinar su propia transacción y comunicarse con otros microservicios para garantizar la consistencia del sistema.
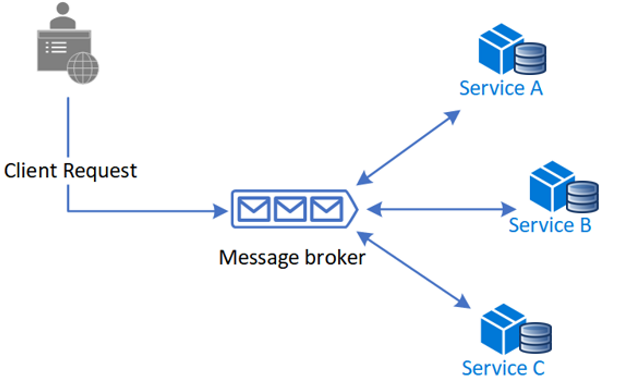
Fuente: https://learn.microsoft.com/es-es/azure/architecture/patterns/choreography
|
Ventajas |
Desventajas |
|
Adecuado para flujos de trabajo simples que involucran a pocos participantes y con una lógica de coordinación simple. |
Más difícil conseguir la trazabilidad. |
| No introduce nuevos servicios dedicados en nuestra arquitectura. |
Riesgo de que se nos produzca una dependencia cíclica. |
| No introduce ningún “single point of failure”. |
Más difícil de testear porque todos los servicios deben estar levantados para simular la transacción. |
- SAGA orquestada: En una SAGA orquestada, un componente centralizado se encarga de coordinar todas las transacciones y comunicaciones entre los microservicios.
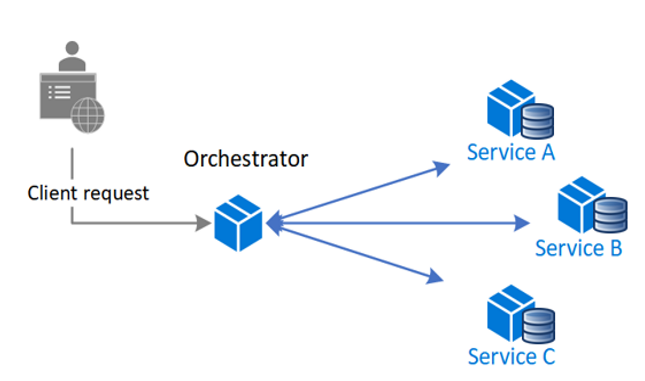
Fuente: https://learn.microsoft.com/es-es/azure/architecture/patterns/choreography
|
Ventajas |
Desventajas |
|
Adecuado para flujos de trabajo complejos que involucran a muchos participantes o nuevos participantes agregados con el tiempo. |
La complejidad adicional del diseño requiere la implementación de una lógica de coordinación. |
|
Adecuado cuando hay control sobre todos los participantes en el proceso y control sobre el flujo de actividades. |
Se introduce un punto adicional de fallo, porque el orquestador administra el flujo de trabajo completo. |
|
No introduce dependencias cíclicas, porque el orquestador depende unilateralmente de los participantes de la saga. |
|
|
Los participantes de la saga no necesitan conocer los comandos de otros participantes. La clara separación de funciones simplifica la lógica de negocio. |
Conclusión
En resumen, una SAGA es un patrón de diseño de software utilizado en microservicios para coordinar una transacción distribuida, en la que intervienen varios microservicios, utilizando un modelo de “consistencia eventual”.
La implementación de una SAGA puede ser difícil y presentar varios retos y dificultades:
- El uso de SAGAs requiere cambiar nuestra forma de pensar en cómo coordinamos nuestras transacciones y de cómo mantenemos la consistencia de nuestros datos. Hay un trabajo previo muy importante de redefinición de los procesos de negocio para intentar que encajen en un modelo de consistencia eventual.
- El patrón SAGA es complicado de depurar, y la complejidad aumenta según el número de participantes. Es vital la incorporación de mecanismos de trazabilidad en nuestra arquitectura de observabilidad.
- Hay que definir bien las transacciones compensatorias y asegurar que tengan la característica IDEMPOTEM (si es posible aplicar esta característica en todas las transacciones locales).
- La falta de “Aislamiento” hace a las SAGAs especialmente sensibles a la concurrencia. Hay que tomar contramedidas para evitar anomalías.
Sin embargo, para sistemas distribuidos complejos que utilizan microservicios, una SAGA puede ser una herramienta útil para garantizar la consistencia del sistema sin comprometer la escalabilidad y disponibilidad.
Referencias:
- Martin Fowler. Sagas. https://martinfowler.com/sagas.html
- Chris Richardson. Microservices patterns: with examples in Java. Manning Publications, 2019.
- Kleppmann, Martin. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. O’Reilly Media, Inc., 2017.


